介绍
- 以往数据库调优是 DBA 在问题发生后进行调整,self-driving (自治)数据库不仅优化当前工作负载,还可以预测以后的负载情况,从而事先做好准备,并且可以为现代高性能数据库提供更多复杂的新的优化方案。Peloton 通过深度学习实现了self-driving。
- 现存的自动调优技术例如:Self-Tuning 物理数据库技术,自动选择索引、自动对表分区存储、自动创建和更新物化视图。自动选择底层存储方式(H2O, 2014),自动设置数据库配置参数,拷贝并及时更新所需索引的DataBase Cracking 技术,云数据库动态资源配置等等。但以上都只用于解决单一的问题,没有从全局考虑,而且 DBA 不一定能了解那么多方面去修复或优化一个系统,而且无法预测未来的负载从而提前做出决策。
问题概述
- 了解应用的工作负载,HTAP(hybrid transaction analytical processing)可能执行事务和查询的时间几乎是同时的,所以不能用为 OLAP 和 OLTP 分别创建一个数据库的方法。HTAP 可自动的选择是使用 OLAP 还是 OLTP 的方式来优化。
- 需要预测资源使用率的趋势。如错开高峰时段进行更新,对即将可能出现的问题提前告警。
- 有了预测能力之后,DBMS 需要为预计的负载情况选择合适的优化方式。Self-driving 不支持需要数据库外部信息(如权限,数据清理和版本控制)的 DBA 任务,支持以下这些操作。对于每一个优化动作,DBMS 不仅需要估计其部署后的开销,还要估计部署它所需要的开销。
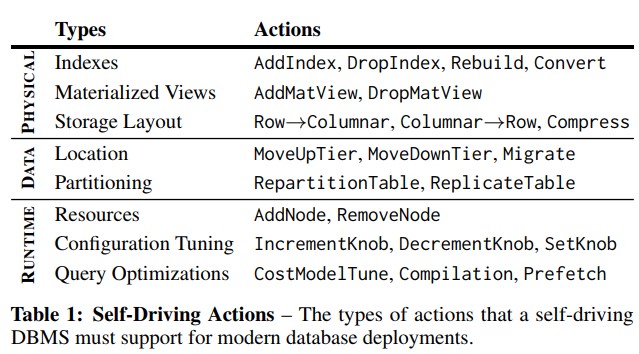
- 需要确定何时生成及采用相应的优化动作。即需要动态学习和改变,以适应负载的改变。
- 两个额外的限制:代码不能因为上层需求改变而需要重构;它不能依赖于仅支持某些编程环境的程序分析工具。
Self-Driving 架构
- 现存的数据库在修改表1 中的Actions时常常需要重启,并且速度也比较慢。自研一个新的DBMS架构能很好的嵌入self-driving组件,并且提供更细粒度的控制。使用多版本并发控制(MVCC)来使得 OLTP 事务不会阻塞 OLAP 查询。使用内存管理、lock-free数据结构和flexible layout使得HTAP工作负载可以快速执行(即 Peloton 的实现)。
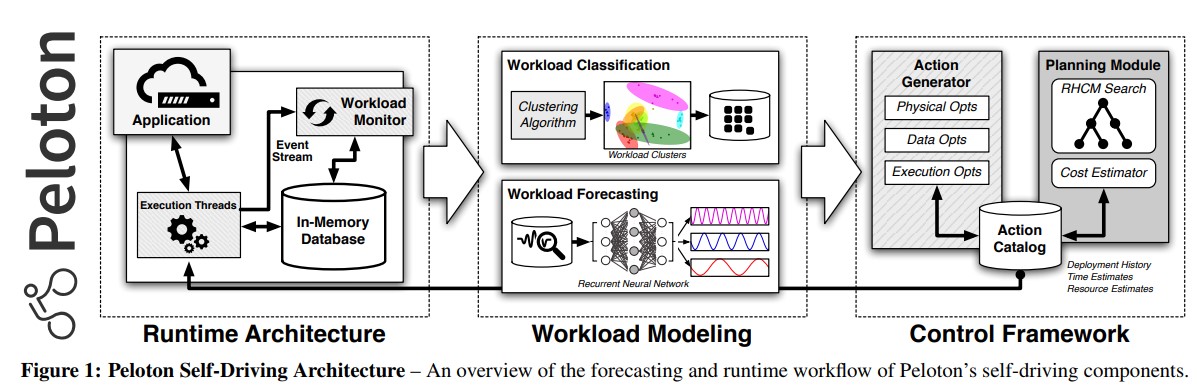
- Peloton架构如Figure 1,系统在不需要任何除环境(例如内存上限,目录路径等)外的其它信息就可以实现自动学习如何降低延迟(数据库最重要的性能指标),目前主要考虑延迟,其它的指标(分布式环境服务开销和能耗)可通过增加限制来优化。
- Peloton中有一个Workload Monitor来监控事件流的资源使用情况和DBMS /OS遥测数据、优化动作的问题出现和结束时机。之后通过这些数据预测负载情况,找出系统瓶颈和其它问题(如索引丢失,节点过载)然后选择最佳执行动作,并且执行的同时进行检测和学习。
负载分类
- 第一个功能组件是通过无监督学习的方式将具有相似特性的应用查询进行聚合,即对负载进行聚类,可以减少模型数量,更容易预测应用行为。Peloton最初的实现是DBSCAN算法(原本用于聚合OLTP负载)。
- 一个很大的问题就是用什么查询特性来进行聚类,有两种:一是查询runtime metrics,虽然这对可以在不需要理解其意义的情况下进行聚类,但是其对数据库内容和底层物理设计的变化更敏感,对高并发的负载也会出现类似的问题;二是查询逻辑语义,基于逻辑执行计划(如表和谓词)来分类,其独立于数据库内容和底层物理设计,但是需要考虑其是否能生成好的模型,并且为了runtime metrics的精度所付出的训练代价是值得的。不过,有可能模型变化不大,收敛快,且由于硬件加速使得开销小。
- 还有一个问题就是如何确定类簇已经不再正确了。Peloton采用交叉验证(留一小部分数据集作为验证集)来确定何时类簇的错误率超过阈值,并且可以探索执行动作是如何影响查询的,从而决定何时重新训练模型。
负载预测
- 为每一种负载的查询的出现率做预测,除了异常的热点之外,这种预测使系统能够识别负载周期性和数据增长趋势,从而为负载波动做准备。在DBMS执行查询之后,它用其簇标识符标记每个查询,然后填充一个直方图,该直方图跟踪在一个时间段内到达每个群集的查询的数量。Peloton使用这些数据来训练预测模型,这些模型估计了应用程序在将来执行的每个簇的查询数量。DBMS还在事件流中为其他DBMS/OS指标构建了类似的模型。
- ARM被用来做时序数据的线性关系分析,但是数据库可能被多个因素影响,并不符合线性假说。
- RNN对预测时序数据的非线性模型很有效。LSTM是RNN的一个变种,可以学习时序数据的周期性规律。
- RNN的准确性依赖于其训练数据集的大小,Peloton为每个Group维护多个RNN(不同的时间范围和间隔)来预测负载。尽管这种粗粒度的RNN不太准确,但是减少了DBMS必须在运行时维护的训练数据的大小和预测所需的开销。
Action Planning & Execution
- 将自动化部件与DBMS进行紧耦合可以使得各部分之间提供反馈。还可以将增强学习应用于并发控制和查询优化
- Action Generation:Peloton会搜索可能提升性能的Action,并且将action及其调用后对系统的影响记录在catalog中。这种搜索是由预测模型引导的,这样系统就会寻找能够提供最大收益的操作。它还可以删除冗余操作,以减少搜索的复杂性。可以根据资源需求及使用情况决定分配多少个CPU核来执行action。Action资源分配的knob为增量更改而非绝对值。某些action还有相应的reverse action,如 add/drop index。
- Action Generation: Peloton会搜索可能提升性能的Action,并且将action及其调用后对系统的影响记录在catalog中。这种搜索是由预测模型引导的,这样系统就会寻找能够提供最大收益的操作。它还可以删除冗余操作,以减少搜索的复杂性。可以根据资源需求及使用情况决定分配多少个CPU核来执行action。Action资源分配的knob为增量更改而非绝对值。某些action还有相应的reverse action,如 add/drop index。
- 在RHCM之下,计划流程(planning process)被组织为树状,每一层包含某个时刻数据库可调用的action,系统根据这些action的成本效益(cost-benefit)来决定调用哪一个action,也有可能一个action都不调用。一种搜索方式是随机选择树上层次更深的action而非评估所有的action(参考alpha go的论文)。对当前数据库状态和预期负载效益更好的action更可能被考虑(加权),同时最近被reverse的action会被避免调用。
- 一个action的开销(cost)是对部署(deploy)这个action的时间和数据库因此性能下降情况的估计。对于没有调用过的action的分析,通过回馈机制分析某一类型的action来改善。一个action的效益(benefit)是在执行(intsall)这个action后在查询延迟上带来的改变,即查询样例的开销加权总和,权重为预测出来的相应查询的到达率。而且时域(time horizon)也会作为权重考虑,这使得直接模型(immediate model)会对最终的成本效益分析有更大的影响。
- 此外,action对Peloton的内存使用率的影响也会在cost-benefit分析的时候考虑,任何导致DBMS内存超限的action都会被忽略。
- RHCM的horizon的值比较微妙,太短的话,在即将到来的负载峰值时DBMS来不及进行准备;太长的话,突然出现的问题无法及时得到优化解决,因为模型太慢了。除此之外,由于计算每个time epoch的cost-benefit是昂贵的,所以可以创建另一个深度神经网络从而用一个值函数来近似它们。
- Deployment:Peloton支持非阻塞地deploying actions。例如,对表进行迁移或重组并不影响其它查询的访问。一些操作,比如添加索引,需要特别考虑,以防在action执行过程中因为因为数据被修改而产生影响。
- DBMS还处理来自集成机器学习组件的资源调度和争用问题。使用单独的联合处理器或GPU来处理繁重的计算任务将避免减慢DBMS的速度。否则,DBMS将不得不使用单独的机器,专门用于所有的预测和计划组件。这将使系统的设计复杂化,并由于协调而增加额外的开销。
Additional Considerations
- DBA对于self-driving的不信任,可以将决策写成人类可读的形式,比如为什么添加索引,它的负载跟之前哪一个很相似,为何添加索引可以带来优化。另外,还需要提示DBA是否需要进行OLTP或者OLAP的优化,以及数据库的重要性优先级。Peloton也会像其它action一样记录DBA的手动操作,并且记录其效益,同时也允许DBA决定此记录何时过时,以防止消除误操作带来长期的影响。